Guida: Sostituzione Disco in un Raid Software (mdadm)
La rottura di un disco in un array RAID software è un evento che ogni sistemista deve saper gestire con freddezza. Grazie all’utility mdadm, la sostituzione di un’unità difettosa su Linux è un’operazione lineare, ma richiede precisione per evitare la perdita di dati.
In questa guida vedremo come gestire la sostituzione di un disco (es. /dev/sda) in un array RAID 1 o superiore.
1. Verifica dello stato dell’array
Il primo passo è controllare lo stato attuale del RAID per identificare quali partizioni sono in stato “degraded”.
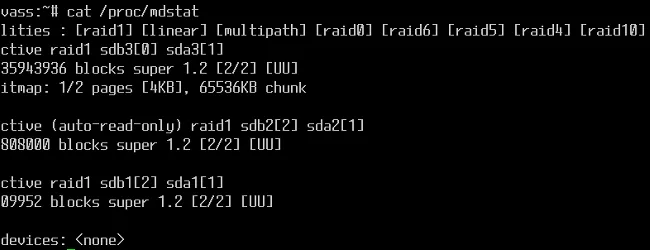
cat /proc/mdstat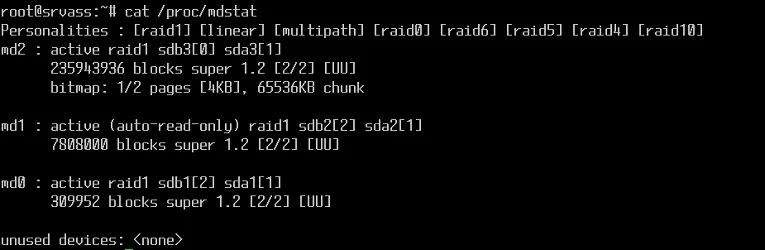
2. Marcare il disco come guasto (Fail)
Se il disco non è stato già rimosso automaticamente dal kernel, dobbiamo marcarlo manualmente come guasto per tutte le partizioni RAID attive:
# Marcare come guasto sda1 nel volume md0
mdadm --manage /dev/md0 --fail /dev/sda1
# Ripetere per le altre partizioni (es. md1)
mdadm --manage /dev/md1 --fail /dev/sda2Controllando di nuovo /proc/mdstat, vedrai lo stato [U_] al posto di [UU], indicando che l’array è degradato.
3. Rimozione e Sostituzione Fisica
Rimuovi logicamente le partizioni dall’array:
mdadm --manage /dev/md0 --remove /dev/sda1
mdadm --manage /dev/md1 --remove /dev/sda2Spegni la macchina (se non supporta hot-swap) e sostituisci fisicamente il disco:
sudo poweroff4. Configurazione del Nuovo Disco
Una volta riavviato il sistema con il nuovo disco vergine, dobbiamo replicare la tabella delle partizioni del disco sano (es. /dev/sdb) su quello nuovo (/dev/sda).
# Copia la struttura delle partizioni da sdb a sda
sfdisk -d /dev/sdb | sfdisk /dev/sda5. Inserimento nel RAID e Resilvering
Infine, aggiungiamo le nuove partizioni all’array per far partire la ricostruzione automatica:
mdadm --manage /dev/md0 --add /dev/sda1
mdadm --manage /dev/md1 --add /dev/sda2Monitoraggio della ricostruzione
Puoi seguire il progresso della ricostruzione (resync) in tempo reale:
watch cat /proc/mdstat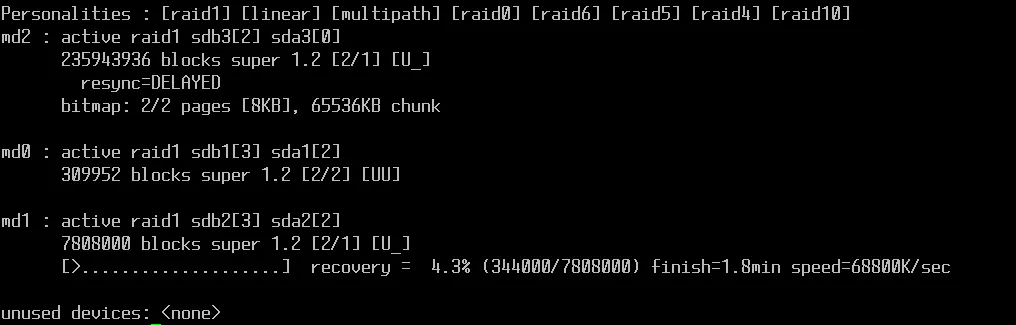
Una volta terminato, lo stato tornerà su [UU] e il tuo array sarà nuovamente protetto.